
OCR
OCR 이란?
"광학 문자 인식"으로 그림이나 사진에 있는 글을 인식하여 텍스트로 변환하는 것을 말합니다.
예를 들어서 외국 간판을 사진으로 찍어서 바로 한글로 번역할 수 있는 것도 OCR의 기술이 적용되었다고 볼 수 있습니다.
GPT-4에서도 OCR의 기능이 있어서 PDF에 있는 글을 추출할 수 있는 OCR이 있습니다.
아래 사진은 육아휴직급여신청서 PDF 파일을 텍스트로 변환해 본 예시입니다.
저작권 없이 사용 가능한 그림이 섞여 있는 PDF 파일을 구할 수 없어 '육아휴직급여신청서'로 예시를 보여드리는데요.
PDF 파일에서는 표로 작성되어 있어 텍스트를 추출하기가 힘들지만 GPT-4의 OCR 기능을 이용하면 쉽게 추출이 가능합니다.
OCR 변환 예시


OCR 변환 사례 (죄측 PDF파일을 우측 텍스트로 변환)
GPT로 OCR 기능을 사용하여 PDF에서 텍스트(글자) 추출하기
1. GPT-4에서 좌측 Explore GPTs를 클릭해 주세요.
2. 우측에 GPTs를 확인하실 수 있습니다.
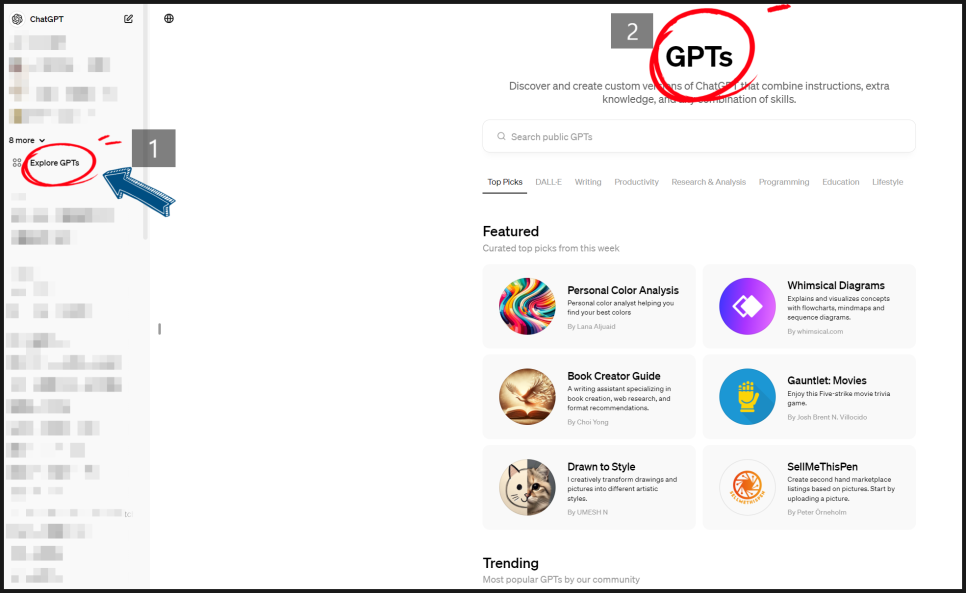
chat gpt를 이용해 ocr 기능을 사용하여 PDF 텍스트 추출하는 방법 01
3. 검색창에 ocr이라고 입력 후 처음에 나온 OCR을 눌러주세요.
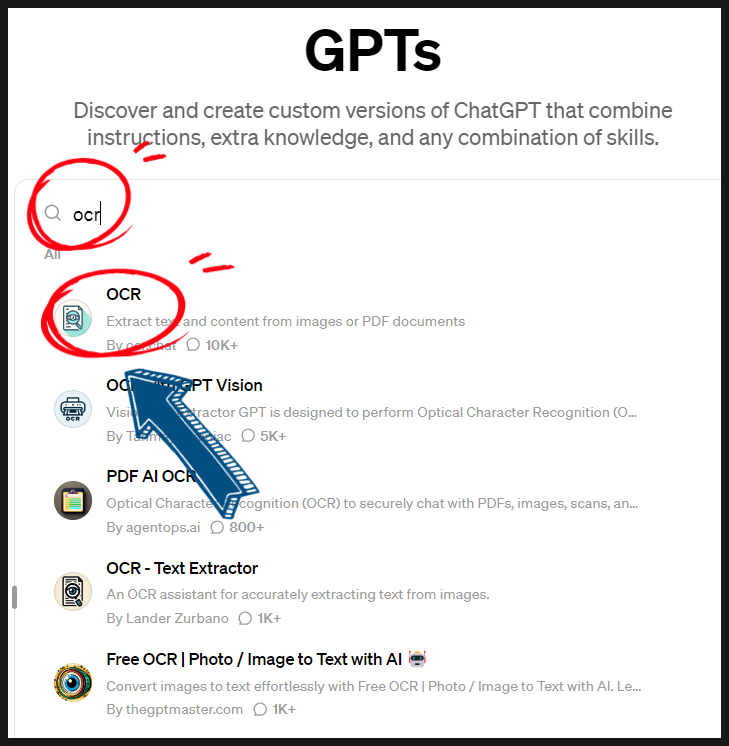
chat gpt를 이용해 ocr 기능을 사용하여 PDF 텍스트 추출하는 방법 02
4. 아래와 같은 화면이 열리면 Start Chat을 눌러주세요.
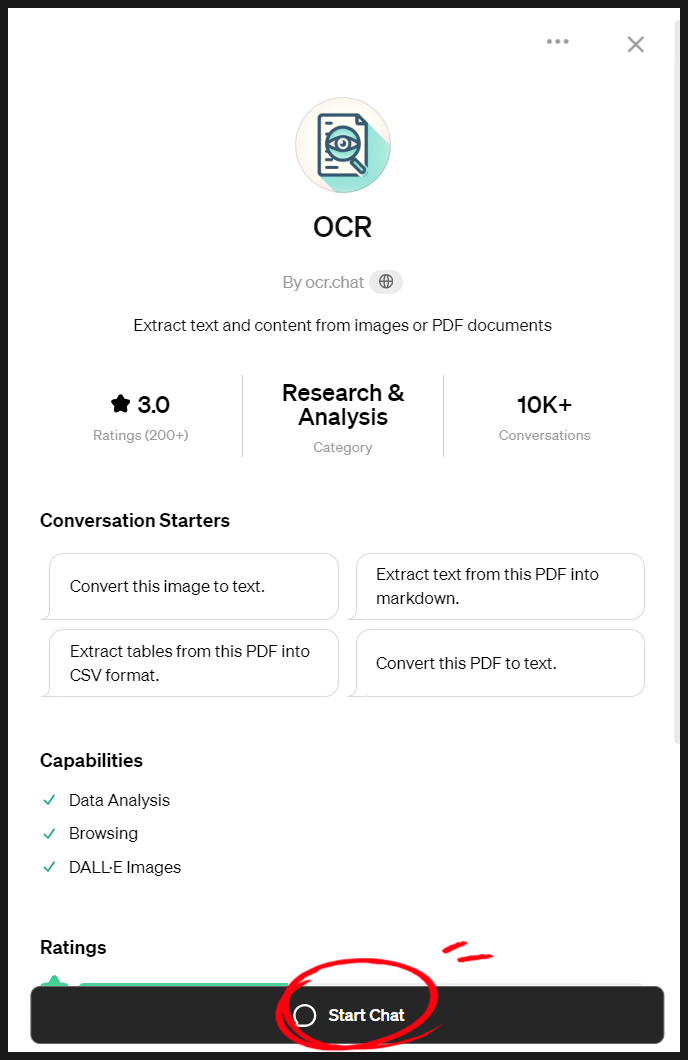
chat gpt를 이용해 ocr 기능을 사용하여 PDF 텍스트 추출하는 방법 03
5. PDF를 텍스트로 추출할 예정이므로 네 번째 버튼 "Convert this PDF to text.'를 눌러줍니다.
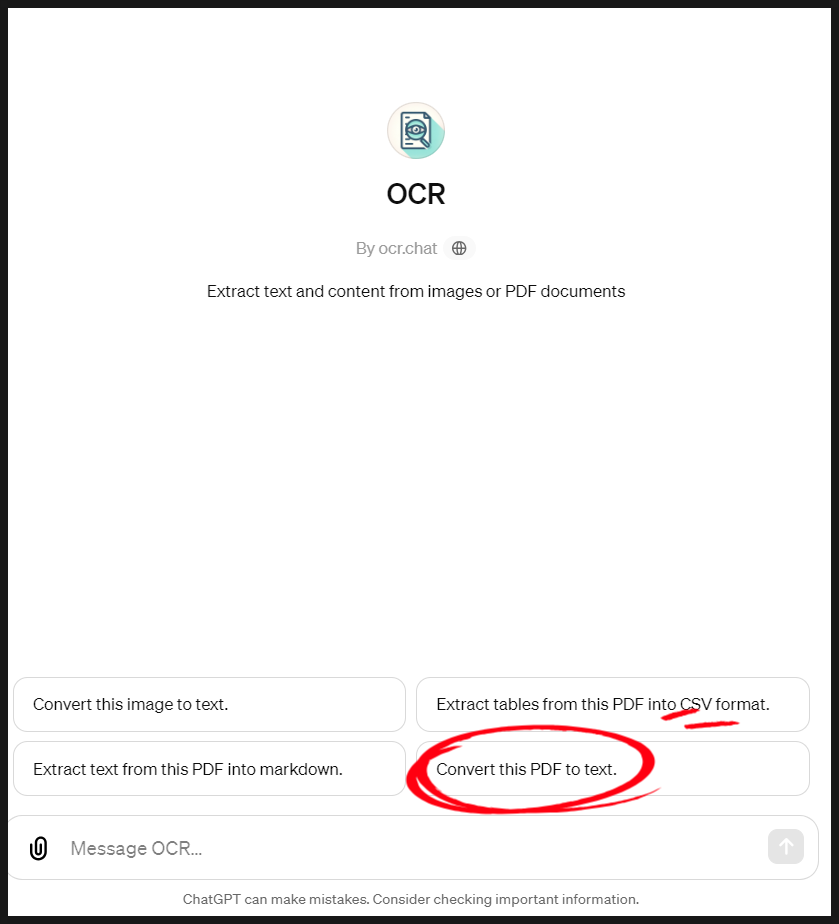
chat gpt를 이용해 ocr 기능을 사용하여 PDF 텍스트 추출하는 방법 04
5. PDF 파일을 첨부파일로 올리고 "한글로 추출해 줘"라고 입력합니다.
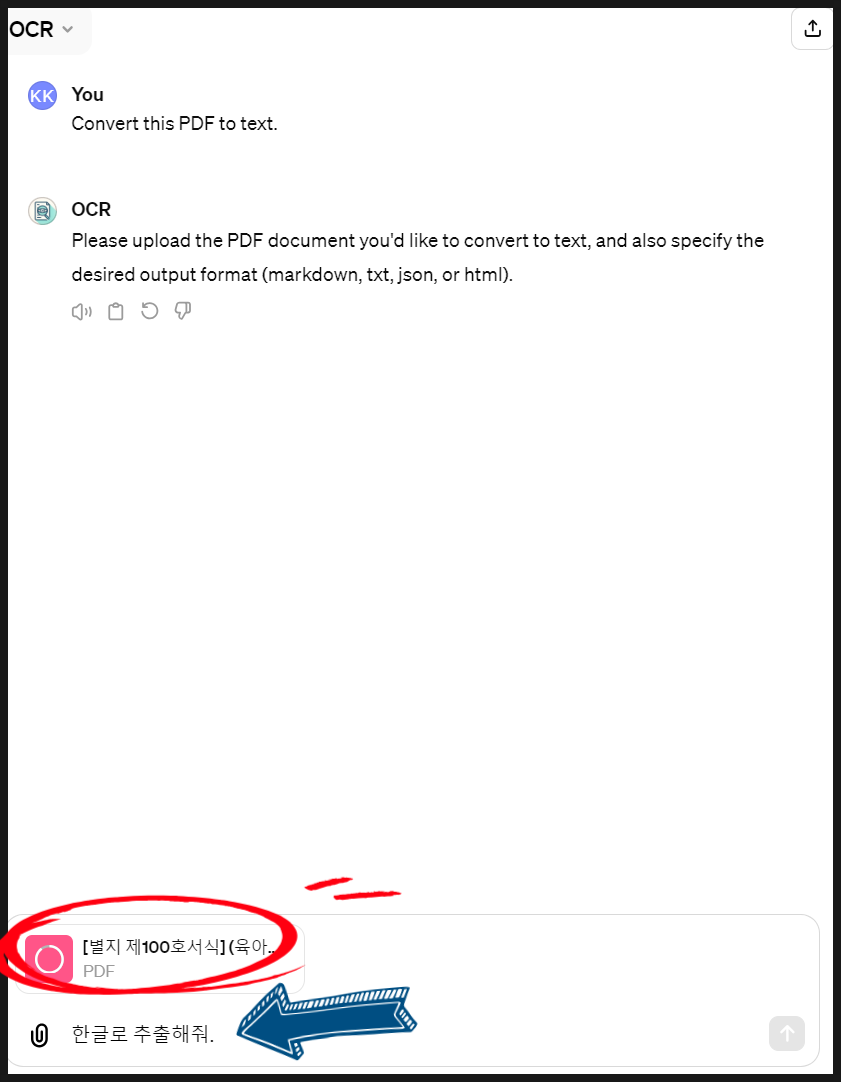
chat gpt를 이용해 ocr 기능을 사용하여 PDF 텍스트 추출하는 방법 05
6. 아래와 같이 한글로 텍스트가 잘 추출된 결과를 확인하실 수 있습니다.
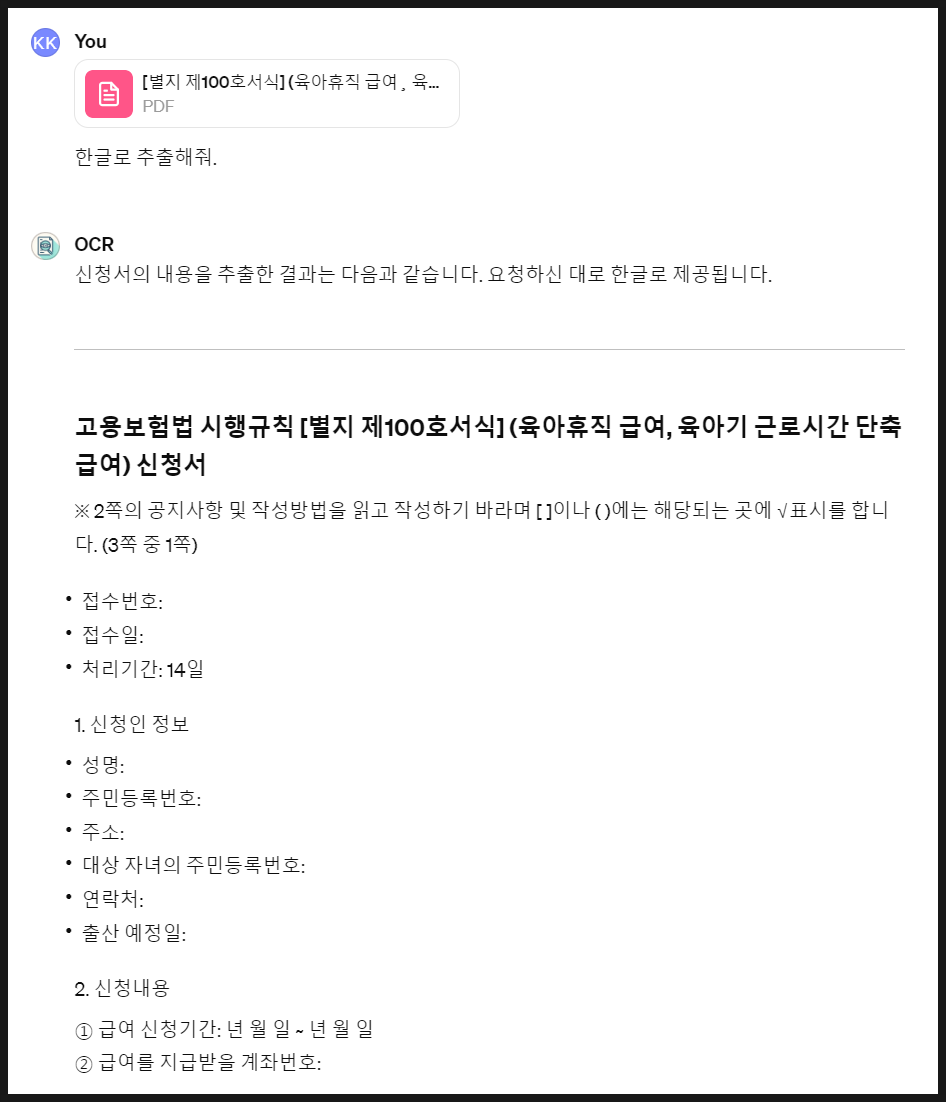
chat gpt를 이용해 ocr 기능을 사용하여 PDF 텍스트 추출하는 방법 06
작은 꿈틀거림으로 함께 역사를 만듭시다.
오늘도 꿈틀🐛

