들어가며
요즘은 종이로 출력된 텍스트를 PDF로 만들어서 태블릿으로 보는 빈도가 높다.
PDF로 만들면 아주 요긴하게 쓰는 기능이 검색 기능이다.
검색 기능을 사용하려면 PDF 파일을 만들 때부터 이 기능을 지원하는 앱을 사용해야 한다.
나의 경우는 Canon 복합기에 번들로 제공하는 Canon Scan Utility를 사용하고 있다.
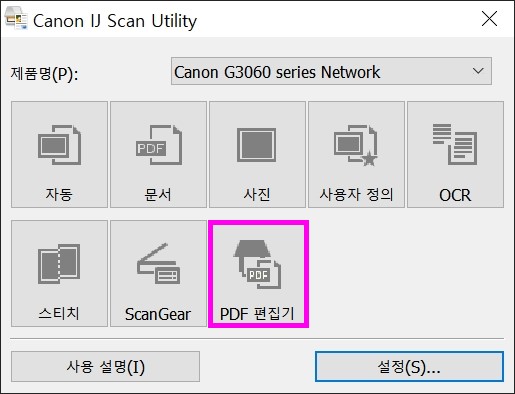
Canon Scan Utility 앱은 PDF 생성 시 '키워드 검색 지원' 옵션을 제공한다.
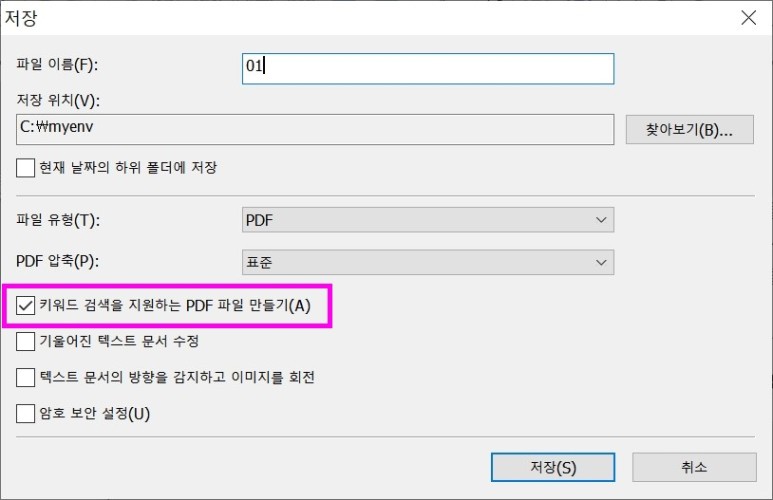
하지만 이 앱은 한 번에 100개의 이미지까지만 PDF로 만들 수 있다는 단점이 있다.
스캔 파일이 100개가 넘어가면 별도의 PDF를 만들고 하나로 합치는 번거로운 과정을 거쳐야 한다.
내가 종이로 출력된 텍스트를 PDF로 만드는 과정은 다음과 같다.
1. 출력된 텍스트를 스마트폰 카메라를 이용해서 vFlat으로 스캔
2. 스캔 한 다음 vFlat에서 테두리의 지저분한 부분 자르기 : 이것을 자동으로 하고 싶음
3. 스캔한 파일을 PC로 이동
4. Canon Scan Utility로 PDF 생성 : 100페이지까지만 가능
5. 생성된 PDF를 태블릿으로 이동 후 갤럭시 노트로 PDF를 하나로 통합
1번 과정은 카메라가 필요하니 어쩔 수 없고,
2번 과정과 4번 과정을 Python으로 자동화하면 편리하겠다는 생각이 들었다.
이번 포스팅에서 Python에서 검색 가능한 PDF 파일을 만드는 방법에 대해서 정리해 보았다.
Python에서 OCR 사용
Python에서 검색이 가능한 PDF 파일을 만들 수 있다.
다만 PDF 파일을 그냥 생성해서는 안 되고 OCR 기능을 적용해야 한다.
대표적인 오픈 소스 OCR(광학 문자 인식) 엔진이 Tesseract다.
처음에는 HP(휴렛 팩커드)에서 개발되었고, 2005년부터는 Google이 주도적으로 개발을 이어가고 있다. Tesseract는 다양한 운영 체제에서 사용할 수 있으며, 100개 이상의 언어를 지원한다.
이 엔진은 이미지에서 텍스트를 추출하는 데 사용되며, 그 정확도와 지원 언어의 폭으로 인해 매우 인기가 높다.
Tesseract를 사용하기 위해서는 먼저 이미지를 전처리하여 OCR의 정확도를 높이는 것이 좋다.
전처리 과정에는 이미지의 크기 조정, 이진화, 노이즈 제거 등이 포함될 수 있다.
Tesseract는 LSTM(Long Short-Term Memory) 네트워크를 기반으로 한 OCR 엔진으로 발전했으며, 이는 텍스트의 형태와 구조를 더 잘 이해할 수 있게 해준다.
Tesseract의 사용 사례는 매우 다양하다.
문서 스캔, 이미지 내의 텍스트 추출, 번호판 인식, 양식 자동화 처리 등 다양한 분야에서 활용될 수 있다.
그러나 OCR 기술의 한계로 인해, 텍스트의 크기, 폰트, 배치, 이미지 품질 등 다양한 요소가 결과의 정확도에 영향을 줄 수 있다는 점을 유의해야 한다.
Tesseract를 사용하는 방법은 명령 줄 인터페이스(CLI) 또는 다양한 프로그래밍 언어를 위한 라이브러리/바인딩을 통해 가능하다.
예를 들어, Python에서는 PyTesseract라는 라이브러리를 통해 Tesseract 엔진을 사용할 수 있다.
이 라이브러리를 사용하면 Python 코드 내에서 직접 이미지 파일을 Tesseract 엔진에 전달하고, 추출된 텍스트를 반환받을 수 있다.
pytesseract는 다른 Python 패키지에 비해 PDF에서 텍스트를 추출하는 이점(예: 단어 사이의 공백 유지)이 있다.
대부분의 Python 라이브러리는 Python 환경에서 pip install로 설치를 해준다.
Tesseract의 Python 라이브러리인 PyTesseract는 Tesseract 엔진에 이미지 파일을 전달하는 역할만 하기 때문에 Tesseract 엔진을 별도로 설치해 주어야 한다.
Tesseract를 제대로 사용하려면 아래와 같이 몇 가지 라이브러리를 설치해 주어야 한다.
1. Tesseract OCR 엔진
Windows와 Python 환경에서 Tesseract를 사용하기 위해서는 Tesseract OCR 엔진 자체를 시스템에 설치해야 한다.
이는 PyTesseract가 단순히 Python에서 Tesseract를 사용할 수 있게 하는 인터페이스일 뿐, OCR 기능을 수행하는 실제 엔진은 별도로 설치해야 하기 때문이다.
Tesseract 엔진을 설치하면, PyTesseract를 통해 Python 코드에서 해당 엔진을 호출하여 이미지에서 텍스트를 추출할 수 있다.
2. PyTesseract
PyTesseract는 Tesseract OCR 엔진을 Python에서 사용할 수 있게 해주는 라이브러리다.
이를 통해 Python 코드 내에서 직접 이미지 파일을 Tesseract 엔진에 전달하고, 추출된 텍스트를 반환받을 수 있다.
PyTesseract는 Tesseract 엔진의 기능을 Python 환경으로 가져오는 브리지 역할을 한다.
3. OpenCV (Open Source Computer Vision Library)
OpenCV는 오픈 소스 컴퓨터 비전 및 머신 러닝 소프트웨어 라이브러리로, 이미지 및 비디오 처리에 널리 사용된다.
OCR 작업에서 OpenCV는 주로 이미지 전처리 단계에 사용된다.
이미지에서 텍스트를 인식하기 전에, 이미지의 품질을 향상시키고 OCR의 정확도를 높이기 위해 다음과 같은 전처리 작업을 수행한다.
이러한 전처리 과정은 Tesseract가 이미지 내의 텍스트를 더 쉽고 정확하게 인식하도록 돕는다.
이미지의 크기 조정
이미지의 크기 조정
이미지의 크기 조정
그레이스케일 변환
그레이스케일 변환
노이즈 제거
노이즈 제거
이진화
이진화
회전 및 기울기 조정
회전 및 기울기 조정
4. pdf2image
PDF를 이미지 객체로 변환하기 위해 pdftoppm 과 pdftocairo를 래핑 하는 Python 모듈이다.
생성된 출력은 이미지 개체 목록입니다.
5. PyPDF2
PDF 페이지 분할, 자르기, 병합 등이 가능한 Python PDF 툴킷이다.
Tesseract 엔진 설치
Tesseract 엔진은 Python이 아닌 Windows 환경에서 설치한다.
(물론 다른 OS도 가능하니 아래의 사이트를 참고하기 바란다.)
먼저 Windows에서 Tesseract 엔진을 설치하는 방법을 알아보자.
아래의 사이트로 들어간다.
Tesseract Open Source OCR Engine (main repository) - UB-Mannheim/tesseract
github.com
위의 사이트에 접속해서 설치 파일을 선택하고 다운로드한다.
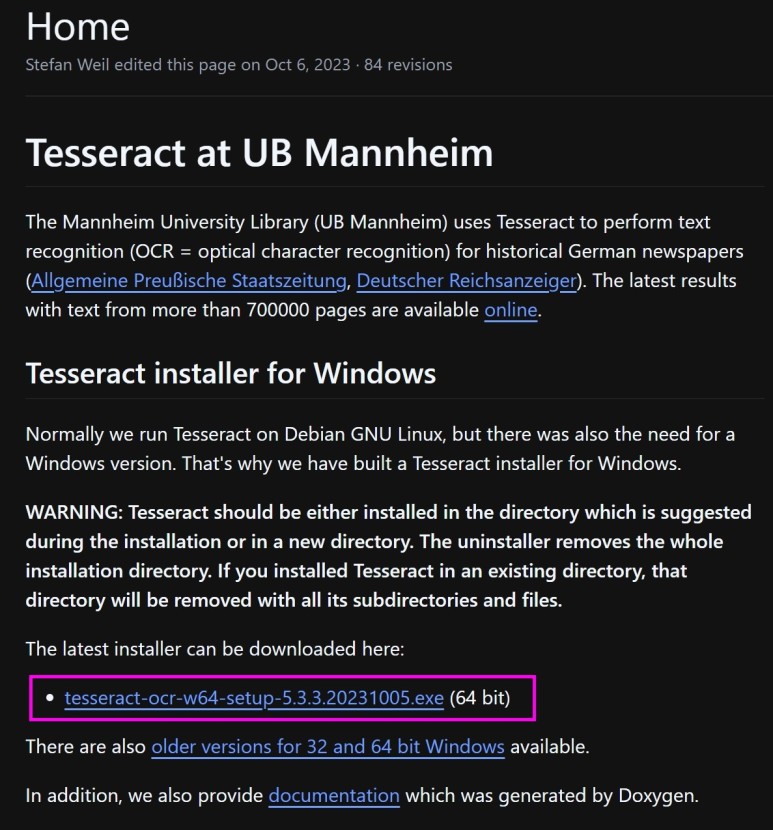
해당 파일을 다운로드 후 설치를 시작한다.
설치 과정에서 'Choose Components' 단계에서 한국어 데이터를 추가로 다운로드해 주어야 한다.
[Additional language data (download)]를 클릭한다.
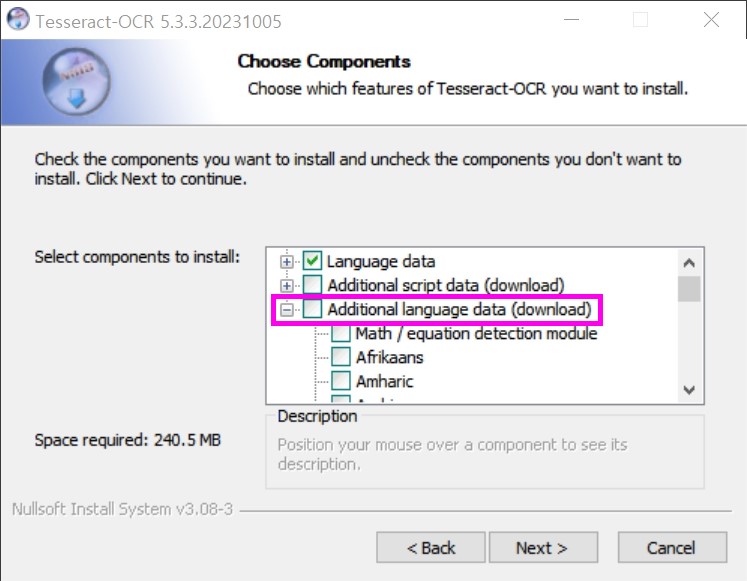
'Korean'을 선택하고 [Next]를 클릭해서 계속 진행한다.
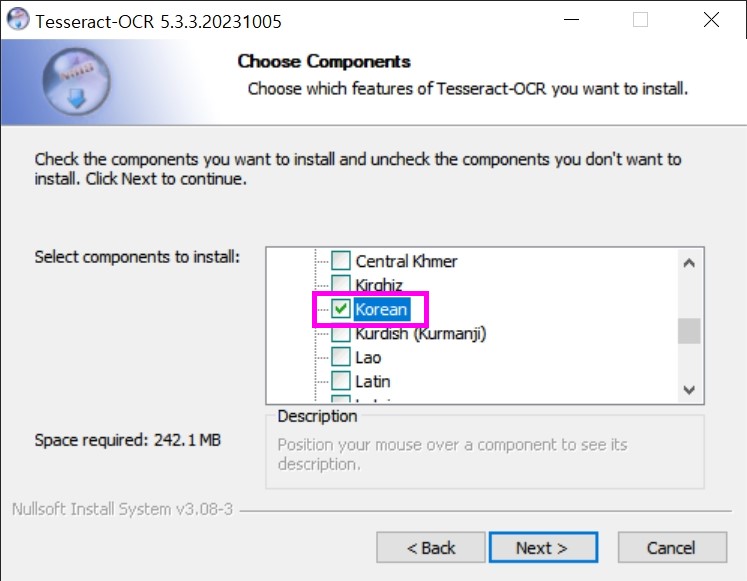
Tessearact 설치 디렉터리는 Python 또는 Python 가상 환경이 설치된 디렉터리를 선택하는 것이 좋다.
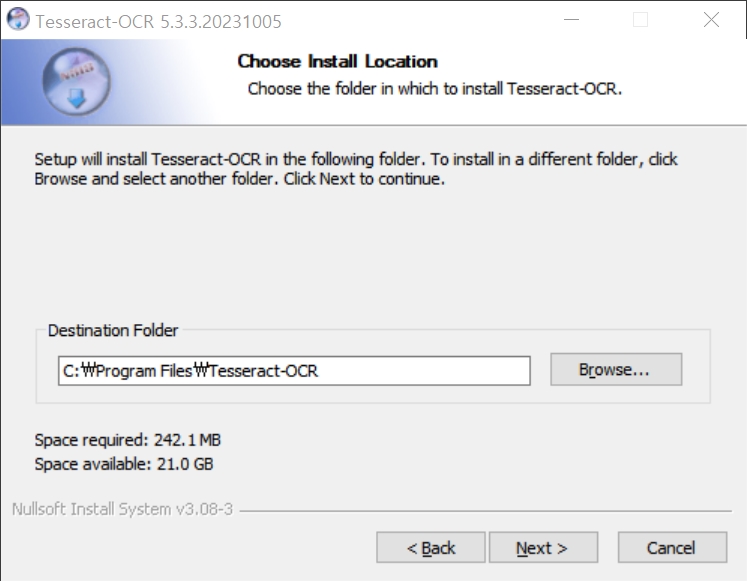
제대로 설치가 완료되면 아래와 같이 "C:\Program Files\Tesseract-OCR" 디렉터리에 'tesseract.exe'파일을 확인할 수 있다.
한국어가 제대로 설치되어 있는지 확인해 보자.
아래와 같이 tesseract.exe 파일이 설치된 디렉터리에서 아래의 명령을 실행하면 된다.
그러면 아래와 같이 설치된 언어가 출력된다.
'kor'가 출력이 되면 한국어 훈련 데이터가 정상적으로 설치가 된 것이다.
참고 : 'OSD'의 역할은?
참고로 위에서 출력된 'osd'는 "Orientation and Script Detection"의 약자로, 출력 결과에서 이미지의 방향, 스크립트(글자 체계), 그리고 언어 탐지와 관련된 정보를 나타낸다.
Tesseract OCR을 사용할 때, OSD 기능은 주어진 이미지나 문서의 텍스트 방향(가로, 세로, 뒤집힘 등), 사용된 스크립트(예: 라틴 알파벳, 한글, 일본어 가나 등), 그리고 가능한 경우 언어를 자동으로 감지하는 데 사용된다.
OSD 기능은 특히 다양한 언어와 스크립트를 사용하는 문서를 처리하거나, 이미지가 올바른 방향으로 회전되어 있는지 확인할 필요가 있을 때 유용하다.
예를 들어, 스캔 된 문서 페이지가 90도 회전되어 있거나, 다양한 언어로 된 텍스트가 포함된 복잡한 문서를 OCR로 처리해야 하는 경우에 OSD를 활용할 수 있다.
Tesseract에서 OSD 기능을 사용하려면, 명령줄 인터페이스에서 --psm (Page Segmentation Mode) 옵션을 0으로 설정하거나, pytesseract 등의 라이브러리를 사용할 때 적절한 옵션을 설정해야 한다.
OSD를 사용하는 것은 텍스트 인식의 정확도를 높이고, 다양한 형태의 문서나 이미지에 대한 처리 능력을 개선하는 데 도움이 될 수 있다.
그러나 모든 경우에 OSD가 필요하거나 유용한 것은 아니며, 특정 작업에 대한 요구 사항과 이미지의 특성에 따라 사용 여부를 결정해야 한다.
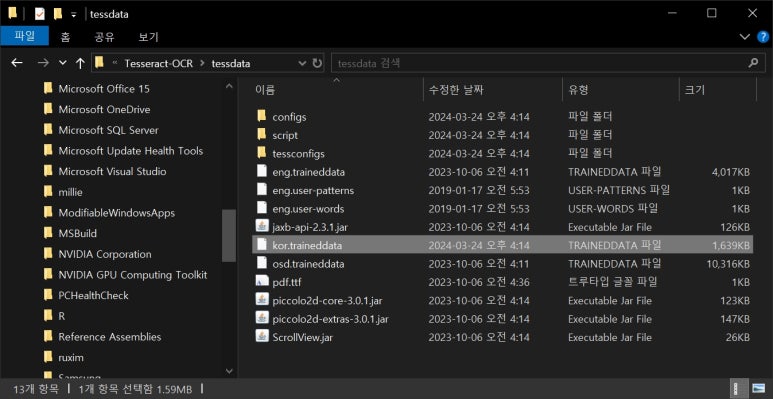
한국어 설치 여부는 디렉터리에서 직접 확인할 수도 있다.
"C:\Program Files\Tesseract-OCR\tessdata" 폴더에서 'kor.traineddata' 파일이 설치되어 있는지 확인하면 된다.
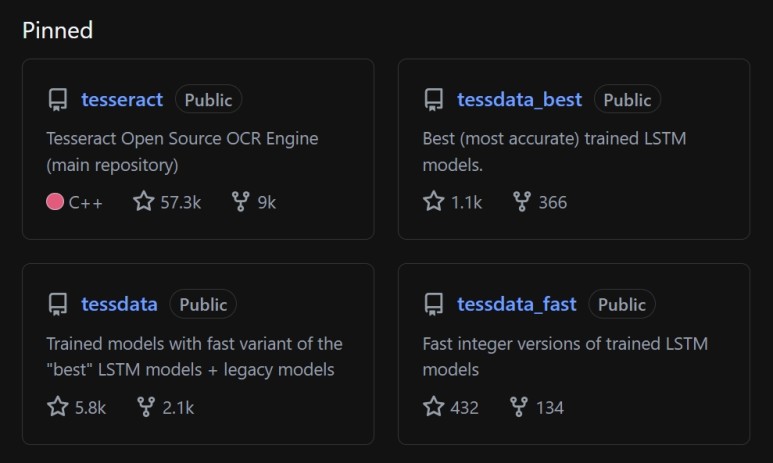
조금 더 정확한 검색을 위해 더 잘 학습된 데이터를 이용할 수도 있다.
아래의 링크로 들어가면 언어별 학습 데이터를 3가지 종류로 제공하고 있다.
기본값으로 설치되는 한국어 학습 데이터는 1번 'Fast LSTM model'이다.
1. Fast LSTM model
2. LSTM + legacy model
3. Best trained LSTM model

Tesseract OCR. tesseract-ocr has 14 repositories available. Follow their code on GitHub.
github.com
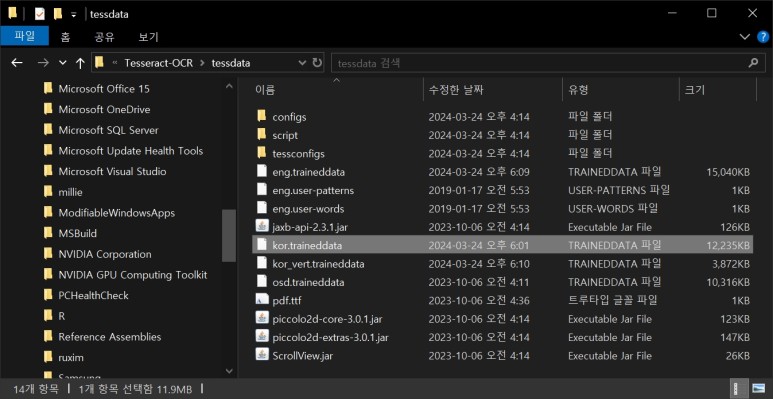
tesseract 엔진 설치 시에 같이 설치된 'kor.traineddata' 의 파일 사이즈가 대략 1.6MB 정도였는데 최고 성능 모델로 변경한 후에는 12MB 정도로 변경된 것을 확인할 수 있다.
PyTesseract 설치
Tesseract를 설치하였다면 이제는 Python에서 Tesseract를 사용할 수 있게 브리지 역할을 해주는 PyTesseract 설치해 주어야 한다.
아래와 같이 설치한다.
OpenCV 설치
이미지 전처리를 위한 OpenCV는 아래와 같이 설치해 준다.
아래는 OpenCV의 기본 라이브러리를 설치하는 명령이다.
기본 라이브러리 외에 추가적인 기능을 사용하려면 아래의 명령으로 설치한다.
pdf2image
pdf2image는 PDF 문서를 이미지 파일로 변환하는 Python 라이브러리다.
이 라이브러리를 사용하면 PDF의 각 페이지를 별도의 이미지 파일로 추출할 수 있다.
pdf2image는 주로 PDF 내용의 시각적 표현을 필요로 하는 애플리케이션에서 사용된다.
예를 들어, PDF 문서를 미리 보기로 보여주거나, PDF 내용을 이미지로 변환하여 OCR(광학 문자 인식) 처리를 하는 등의 작업에 활용된다.
pdf2image 는 다음과 같이 설치한다.
PyPDF2
PyPDF2는 Python에서 PDF 파일을 다루는 데 사용된다.
이 라이브러리는 PDF 문서를 읽고, 분석하고, 수정하고, 생성하는 기능을 제공한다.
PyPDF2는 그 자체로는 OCR(광학 문자 인식) 기능을 제공하지 않지만, OCR을 통해 생성된 텍스트 데이터를 포함하는 PDF 문서를 생성하거나 수정하는 데 사용될 수 있다.
예를 들어, PyTesseract와 같은 OCR 라이브러리를 사용하여 이미지에서 텍스트를 추출한 후, PyPDF2를 사용하여 이 텍스트를 포함하는 검색 가능한 PDF 문서를 생성할 수 있다.
PyPDF2는 다음과 같이 설치한다.
키워드 검색 가능한 PDF 파일 만들기
책의 일부를 스캔 한 이미지를 키워드 검색이 가능한 PDF로 만들어 보자.
여기에서는 Tesseract 를 중심으로 설명한다.
EasyOCR이나 의 Clova OCR도 텍스트 추출 기능을 제공하지만 검색 가능한 PDF를 만드는 데는 아직 성공을 못했다.
아래의 3가지 'kor.trainddata'를 모두 적용해서 PDF를 만들고 한글 검색 성능을 비교해 보았다.
1. Fast LSTM model
2. LSTM + legacy model
3. Best trained LSTM model
생성한 PDF 파일을 크롬 브라우저에서 열어서 '출력'이라는 단어로 검색을 해보자.
PDF 파일에는 '출력'이라는 단어가 4개 포함되어 있다.
모델별로 검색 되는 단어의 수가 다르다.
1. Fast LSTM model : 2개 검색
2. LSTM + legacy model : 0개 검색
3. Best trained LSTM model : 2개 검색
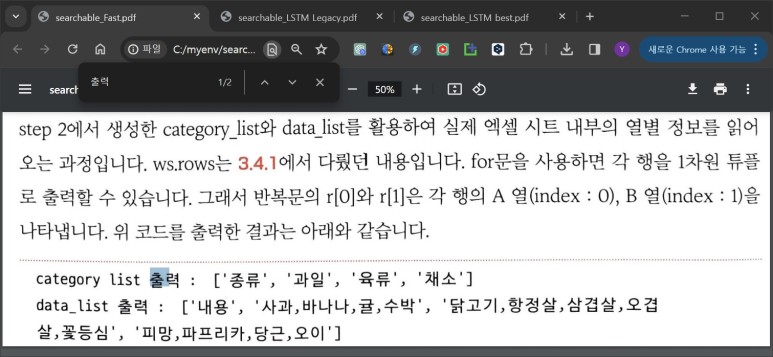
약간 실망스러운 결과다.
그런데 동일한 PDF 파일을 태블릿으로 옮겨서 삼성 노트에서 검색해 보았더니 만족스러운 결과가 나왔다.
삼성 노트에서는 4개의 '출력' 키워드가 모두 검색이 되었다.
PDF 파일을 만들 때 키워드 검색이 가능하도록 OCR 을 적용하는 것도 중요하지만 PDF 파일을 읽는 리더 앱의 기능도 중요하다.
| 파이썬 스크립트
| 소스 이미지
| 파이썬 스크립트로 생성한 PDF 파일
3개의 한국어 데이터 세트를 이용해서 생성한 PDF 파일들이다.
나가며
이번 포스팅에서는 Python의 Tesseract 라이브러리를 이용해서 100페이지 이상의 이미지를 키워드 검색이 가능한 PDF 파일로 만들 수 있는 가능성을 확인했다.
이번 포스팅에서는 Python의 Tesseract 라이브러리를 이용해서 100페이지 이상의 이미지를 키워드 검색이 가능한 PDF 파일로 만들 수 있는 가능성을 확인했다.
이번 포스팅에서는 Python의 Tesseract 라이브러리를 이용해서 100페이지 이상의 이미지를 키워드 검색이 가능한 PDF 파일로 만들 수 있는 가능성을 확인했다.
다만 Best trained LSTM model을 사용할 경우 270페이지를 PDF로 만드는데 약 15분 가량이, Fast LSTM model은 약 9분이 소요되었다.
다만 Best trained LSTM model을 사용할 경우 270페이지를 PDF로 만드는데 약 15분 가량이, Fast LSTM model은 약 9분이 소요되었다.
변환 속도를 좀 더 빠르게 할 수 있는 방법을 좀 더 찾아봐야 할 것 같다.
변환 속도를 좀 더 빠르게 할 수 있는 방법을 좀 더 찾아봐야 할 것 같다.

